摘要
尺度变化是目标检测领域中的重要挑战之一。在本文工作中,我们做实验研究了目标检测中感受野对于尺度变化的影响。基于这些实验结论,我们提出了一种新颖的三叉戟网络(TridentNet),旨在生成特定大小的特征图。我们构建了一个多支路并行的网络结构,每个分支共享参数但感受野不同。之后对于每一条分支,我们将目标采样到合适的尺寸用于训练。我们还提出了一个快速版的TridentNet(置用一条支路进行推理),这个网络在不需要额外参数和计算成本的前提下可以显著提高典型检测框架的性能。在COCO数据集上,我们提出的基于ResNet-101主干网络的TridentNet可以达到单模型48.4mAP最好成绩。代码开源在:https://git.io/fj5vR。
动机
- 目标检测中的对象大小变化范围很大,会一定程度上影响检测性能。尤其是那些太大或太小的目标,对检测性能的影响很大。
- 图像金字塔(下图a)和特征金字塔((下图b)是处理多尺度问题的两个有效思路。图像金字塔通过在训练和推理阶段使用不同大小的图片进行输入,可以提高检测精度,但是也带来了推理时间的成倍增加,因此在实际应用中并不合适;特征金字塔(如SSD、FPN)利用不同深度的特征图信息进行预测(SSD从当前层预测、FPN引入横向连接跨层融合特征信息预测),但由于FPN的融合的特征来源于不同的层,使用的参数不完全相同,因此不能完全作为图像金字塔的替代品(图像金字塔所有的图片经过相同的推理过程,使用的参数一致)
- 图像金字塔和特征金字塔的主要思想基本一致,即对于不同大小的目标,模型的感受野应该也有所不同(大目标的感受野应该大一些,而小目标的感受野应该小一点)。不同的是,图像金字塔充分利用了模型的表达能力,所有大小的目标都通过一致的模型推理过程,但推理时间成倍增加;特征金字塔融合了不同深度的特征,导致了特征的不一致性,可能会降低模型训练效率,同时增加过拟合的风险(???)。
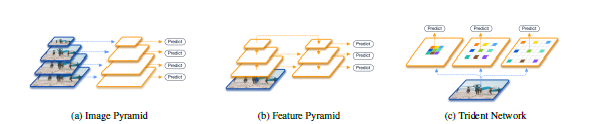
主要工作
感受野对检测的影响
为了更直观地量化目标检测中感受野变化对检测结果的影响,论文首先设计了一组实验。实验基于COCO数据集,并采用基于ResNet-C4的Faster R-CNN。然后将主干网络中的部分卷积过程用膨胀卷积来代替,使用不同大小的膨胀率来控制感受野的大小。论文的实验结果如下:
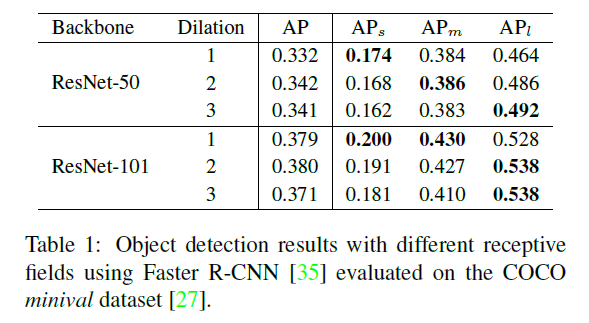
从上表结果中可以看出,不论是ResNet-50还是ResNet-101,在膨胀率从1开始逐步增加到3时,模型对小目标的AP值逐渐下降,对大目标的AP值逐步提高。换句话说,感受野小的模型对小目标的检测性能较好,而感受野大的模型对大目标的检测性能较好。这也正是论文中提出TridentNet的主要动机。
TridentNet框架
模型设计
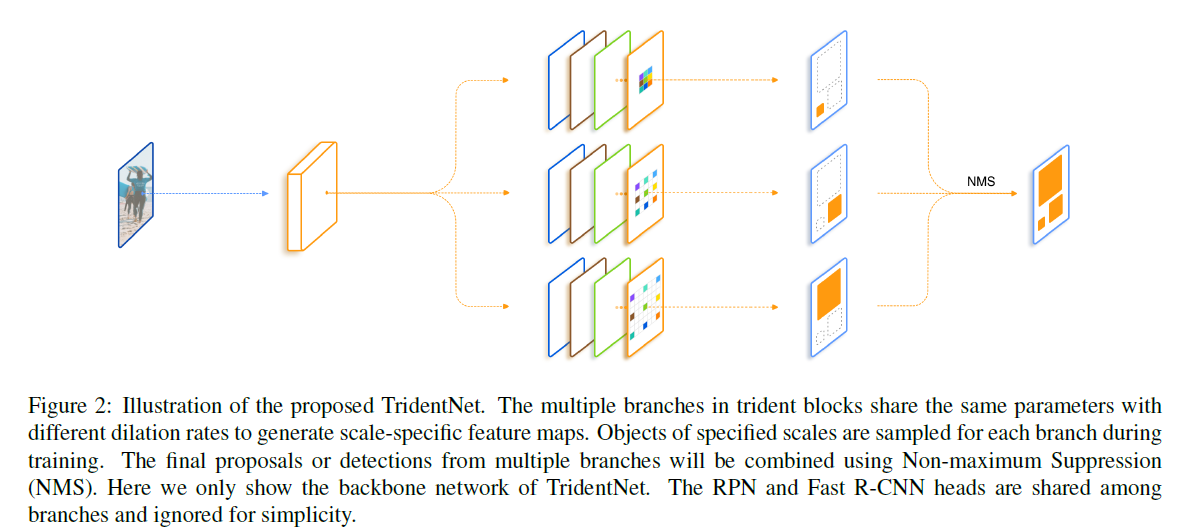
TridentNet结构最核心的思想是模型感受野大小需要和目标大小相互匹配。而为了达到这一目的,最直观的想法是让特定感受野的模型只负责和它相匹配的目标的训练。但是如何让单个模型有不同的感受野呢?TridentNet的策略就是分支网络+膨胀卷积。
上图中,图片进入网络后,在进入主干网络的若干层后,分3条支路,每条支路都结构相同,但膨胀卷积的膨胀率不同(例如对于ResNet主干网络,将最后一个stage的卷积换成膨胀卷积,然后分三条支路),输出特征图的每个位置的感受野也不同,最后将3条支路的所有输出结果进行非极大值抑制,得到最终结果。
到这里可能会有一个疑问:分三条支路,那训练的参数量不会成倍增加吗?TridentNet其实也考虑到了这个问题,并且给出了解决思路:分支权重共享。如下图中,多条支路中,所有的结构完全相同,不同的只是膨胀卷积的膨胀率不同,所以参数共享是完全可行的。更具体地说,候选框不论进入那条支路,更新的参数都会共享到其他所有支路上。这样的好处在于,对于某一个输入,网络使用最合适的膨胀率的支路进行前向传播和参数更新。
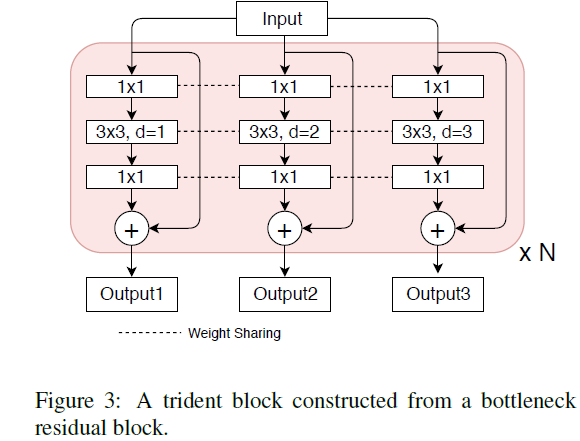
那现在又引出一个问题,如何让网络针对不同大小的候选框选择特定的膨胀率的支路呢?TridentNet给出的方法给每条支路设定一个大小阈值,然后根据输入候选框的大小,分配到相应的支路中,即:
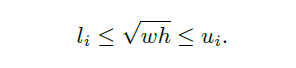
模型推理
对于模型推理,最直观的思路是使用所有支路的预测结果,最后在一起进行非极大值抑制,但这样做会显著增加推理时间。因此,论文中也给出了一个快速推理的方法,即只是用其中的一条支路进行预测。例如对于3条支路的TridentNet,只使用中间那条支路进行预测,因为中间支路膨胀率比较适中,可以兼顾较大和较小的目标。而论文在实验中也发现,只使用一条支路进行预测也并没有牺牲太多的检测精度。
实验
实验实现细节
- 以Faster R-CNN为基础框架,并基于MXNet实现。
- 模型输入图片短边会被Resize到800
- 训练阶段采用随机水平翻转
- 训练采用8块GPU,每块GPU2张图片
- 初始学习率0.02,第8轮和第10轮依次衰减1/10
- 每条支路在NMS前最多生成12000个候选框,NMS后最多保留500个候选框,并选取128个候选框用于训练
- 采用三条支路,膨胀率依次为1,2,3,$\sqrt(wh)$ 的范围依次为[0,90],[30, 160],[90, ∞]
主要实验结果
论文首先基于ResNet-101和ResNet-101-Deformable主干网络研究了TridentNet框架中几个重要的超参数的影响,如是否采用多分支、是否权重共享、是否按候选框大小分配分支等,结果如下:
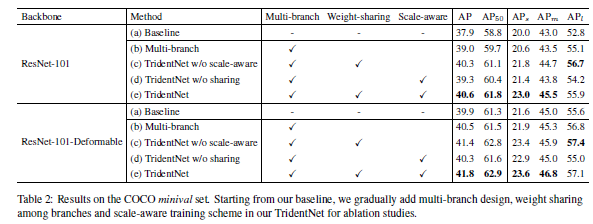
可以发现,在两种主干网络上,采用TridentNet中提出的几种策略对Baseline都起到了明显的提升效果。唯一不足的是,scale-aware策略在$AP_l$指标上略有牺牲,文中也指出这一点可能是由于按大小分配候选框会导致每条支路上有效的样本数量下降,导致过拟合。
文中也比较了TridentNet和其他主流检测框架的性能,如下图:
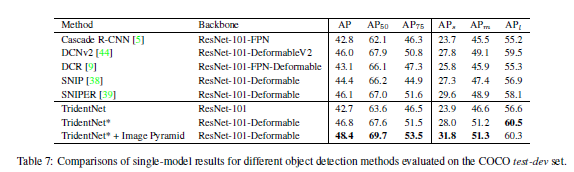
从上表中可以看出,采用ResNet-101-Deformable主干网络的TridentNet在COCO数据集上的表现是非常亮眼的,而如果在推理阶段再采用多尺度测试,性能又得到了明显提高。
总结
TridentNet的出发点是为了解决感受野大小和检测目标大小的不一致问题。大的目标需要大一点的感受野,而小目标的感受野不宜太大。为了解决这个问题,TridentNet采用多分支结构,每条分支采用不同膨胀率的膨胀卷积来实现不同的感受野。其实我觉得这种处理思想和Cascade R-CNN很像,都是为了保证模型和数据的”一致性”,只不过Cascade R-CNN针对IOU阈值,而TridentNet针对感受野。